|
|
|
2009-2010 Planning
September, 13th, 2009
- MPM (october, due august): RAM process and Higher-order transformation
- SIMUTools (march, due october): Modelling a distributed DEVS simulator as a DEVS model with fault-tolerance capabilities
- Research proposal exam (november)
- GT-VMT (march, due december): T-Core and primitive transformation languages
- ICMT (july, due january): MoTif-Core from T-Core and Exceptional transformations
- ICMT (july, due january): Parallelizability of model transformation patterns and Precise semantics of parallelism in MoTif
- Transactions of SCS (december): Simulating a distributed DEVS simulator with optimal partitioning and fault-tolerance
- Research visit in Antwerp (may...)
Distributing DEVS for Model Transformation
January, 23rd, 2009
- Comprehensive exam post-mortem: final document.
- PADS submission.
- Extension of modelled distributed DEVS simulator to MoTif transformation.
- -> Case study of CD2RDBMS.
- NII or DAAD (latter only for undergraduates).
Distributing DEVS for Model Transformation
Novembre, 14th, 2008
Having successfully modelled an AtomicSolver, a Coordinator and a RootCoordinator as atomic DEVS models,
we have discussed how a distributed environment can further be modelled.
This involves having: Local Coupling Table (for local port mappings), Remote Coupling Table (for remote port mappings over the network),
Model Repository Server (where the model to simulate lies), Log Server (keeping a trace of events processed and transitions performed),
Live Server (checking which node is in failure), Save Server (where the state of each simulator is saved) and a "God" Server which initializes the simulation.
We have also identified what possible fault-tolerance statistics can be collected from simulating such an environment.
For example, performance versus time-out because often the Coordinator does not know how long it should wait before time-out assuming its influencee failed.
Thus, in the real distributed DEVS, it can simulate the possible scenarios with different time-outs and figure out which one is a better choice.
A distributed version of MoTif is desired when, in the presence of a Selector, at most one of rules R1 & R2 must be applied.
Another case is when threads of transformation are run in parallel and later synchronized by a Synchronizer.
Suppose the first thread consists of R1 and the second of R2.
R1 & R2 better be parallel independent. How to check that? Several approaches may be considered:
- Run a conservative static critical pair analysis on the structures present in the rules:
check that LHS(R1) n RHS(R2) = 0 and LHS(R2) n RHS(R1) = 0 (of course taking in consideration NACs).
But this is only a sufficient condition because it can give a false positive answer.
- A more thorough check for parallel independence can be done through full exploration/simulation of R1 and R2,
considering the constraints (evaluable at run-time).
- A third alternative is to effectively do a full dynamic check and if a conflict is detected,
the modeller can specify a block for handling this conflict.
This is analogous to handling exceptions in programming languages, but in this case,
the "throw" of exception is modelled to trigger the "catch" model that handles such a parallel independence conflict.
An advantage of distributing DEVS for model transformation is interoperability.
DEVS can serve as a "bus" or middleware where the transformation of a model can be scaled onto different transformation tools.
Providing a (2-way) adapter for each tool, the transformation can flow in a MoTif model,
be then fed to another tool after which the transformation continues within MoTif...
A chain (in the form of a control flow) of transformation "packages" can be constructed as such, taking advantage of each tool to what it is best for.
This can be done using a distributed DEVS as a foundation for the transformation cycle.
Publications
October, 24th, 2008
- SoSym: MoTif
- Transactions of SCS: GPSS + PiDemos (HV associated ed.)
- JCCBS or MoDELS: Security (January)
- ICMT: MM of MT & HOT -> Jeff Gray (January)
Planning
July, 22nd, 2008
- P0: back-link to AToM3
- P1: Kernel, Efficiency
- P1.5: "Regular Expressions" for Patterns
- P2: Distributed
- P2.5: Hierarchy
- Triple Rules
- Declarative Composition ~ Algebraic relations between attributes
- Database Implementation
- Higher-Order Transformations
Publications to aim in 2009
- MoDELS, ICMT, GT-VMT
- SoSym, SCP, TSE, SP&E
- TOMACS, T. Simulation, SIMPRA
Extending GRCF (with DEVS) by modelling the User
October, 19th 2007
-
GHOST++
Modify the graph grammar to have a smarter ghost
-
ta (g)
Use time as a metric. The metric will be the "time to live"
-
TRACE++
Pass along the graph instead of the rules.
Two ports are needed:
- 1. Send the graph after a rewrite
- 2. Query the current state (graph)
We need an external API of helper query methods on the graph.
Whenever the user sees a change, try to react with delay
-
USER++
Have different user levels: random, smart, fast, slow ... user
-
Real-Time
Using R-T DEVS, user reaction time delayed for
- 1. Hitting the button
- 2. Reaction to change of graph configuration
-
User Interface
Stand-alone python (pydevs) code + static SVG + code to link. See with Jake.
Build table of performance by changing the parameters for the simulation
The main disadvantage of our approach is that DEVS makes a copy of each graph before it is sent to a block: Inefficient.
AToM3's new meta-meta-model
October, 3rd 2007
Our MOF should be something like Ecore, which is typed by Ecore.
But the meta-model should include:
- classes
- actions
- constraints
So Ecore = Class Diagram + pre-condition + post-condition + invariant
Ecore must be implemented in Himesis.
And Himesis will be designed in class diagrams (but this is on the side).
Implementations for the thesis
September, 7th 2007
-
Build a Progrmammed Graph Rewriting Control Flow modelling environment based on DEvS.
-- Done.
-
Meta-model the TGG formalism and build a graph grammar that transforms a TGG into a
traditional GG. First a single TGG, then a flow of TGGs into a GRCF model.
Publish a paper in GT-VMT on that. The contribution is on the way of linking the different GGRules
that represent a TGG.
-
AToM3 revised.
Each Meta-model should be mapped on an Abstract Syntax Hierarchical Graph (ASHG).
This ASHG must then be compiled into a Himesis model.
So there needs to be a disucussion on what this ASHG will be
(class diagrams, with constraints, action language, ...).
-
Optimize the matching (interpretted //vs// compiled), of course using the "very efficient" Himesis matching algorithm.
TODO for the summer
July, 3rd 2007
-
Based on the DEVS graph rewriting project (COMP 522), automate the translation of AToM3 rules
to the python code in the DEVS blocks.
The code generation can be naïve.
Add a pivot to input and output of each GG rule: pass the node where the match has succeeded, otherwise pass None.
-
Build the GRCF (Graph Rewriting Control Flow) in the AToM3 environment.
Construct the Meta-Model and its modelling environment.
The model only contains atomic and coupled devs blocks for rules. No user, no controller.
-
Think about an eventual Kiltera paper.
-
Generate everything in Himesis (instead of ASG): first by hand, then automatically.
Refer to Philippe Nguyen's work.
-
Optimize the matching (interpretted //vs// compiled), of course using the "very efficient" Himesis matching algorithm.
-
Replace the GG rules (traditional graph grammar rules) by TGR rules (Triple Graph Rewriting rules).
This is a GG rule whose LHS and RHS are Triple Graphs.
-
Integrate pure Triple graph grammars (at the Meta-Model level, Schür's way).
Investigate automatic transformations from TGG -> TGR R.
Don't neglect the declarative attribute relations...
PiDemos Publication
March, 23rd 2007
-- revised April, 13th 2007
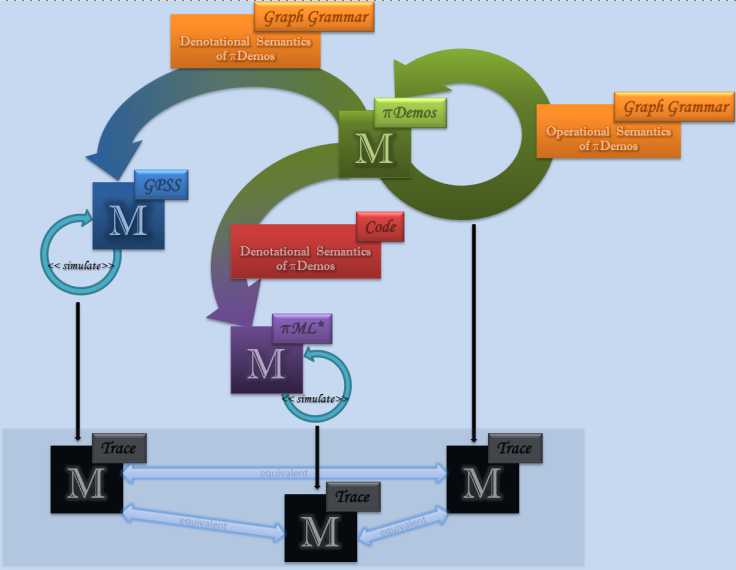
-
piDemos + GG => operational semantics (updates the state of pidemos model, stays within piDemos)
nice visual animation of the behaviour
=> with very little effort, map to GPSS. GG rules are almost 1-1 (seize, release, ...)
done by syntax mapping, the behaviour is the same!
- no interrupt in pidemos
+ pidemos can now be used professionally
-
pidemos compilation to ML => compare trace of GG, of Birtwisle simulator, of GPSS simulator results
-
piDemos language is a subset of the GPSS language.
-
Contribution: pidemos --GG--> pidemos: animation aspect of a simulated model.
- experimient with (already existing) languages
- immmediate animation, simulation
- map onto code => in no time have a visual editor for pidemos
Related work: reading about GG's, GG tools, what was done with pidemos & gpss, simulation tools
Intro: GG, piDemos, GPSS
Developpment: describe these GG tranformation and how they work (example of the way bridge, used in the pidemos paper)
Graph Rewriting + MM: behind the back of my MM, I add attributes to my model:
- augment MM with extra-attributes (ex: hasBeenVisited, ...)
- modeler point of view: only used for the GG execution, not kept in saved model -> transformation side
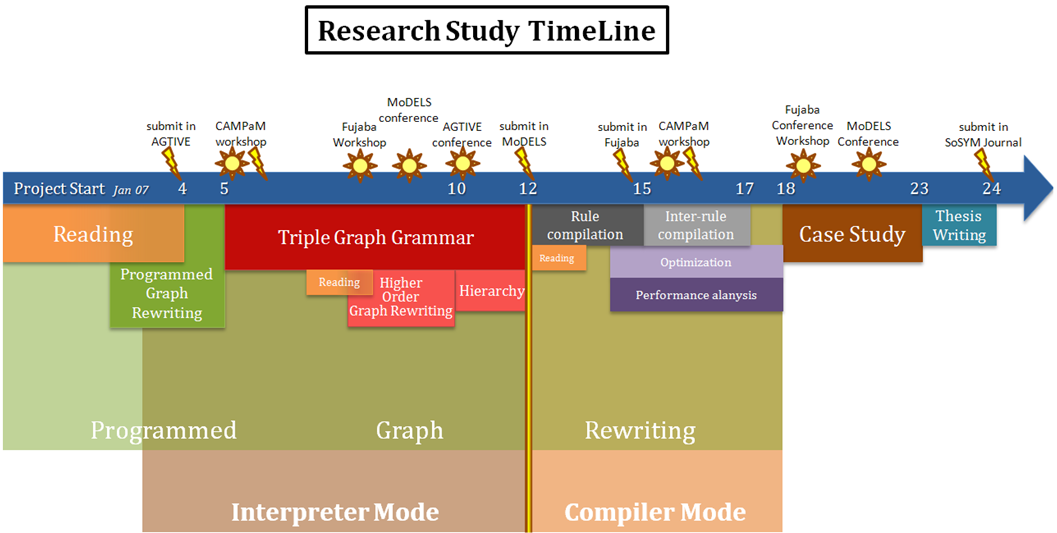
Reserach Thesis TimeLine
March, 9th 2007
List of references to read
Overview of the Topics to study
November, 16th 2006
-- revised February, 1st 2007
Thesis Meta-model
September, 22nd 2006
-
A thesis is divided in 4 parts:
-
Reading:
This is the part where you talk about what already exists in the litterature,
what work has already been done. It is to give the background of what we have until now
and put in the context.
-
Focus:
This is the part where you show what you have done but theoretically speeking.
All the formal explanations, definitions, ... are to be mentionned here.
-
Implementation:
This is the part where you show what you have done but practically speeking.
What you have built, showing snapshots and explanations.
-
Case Study:
This is the part where you show that what you have done actually works!
That it is useful. You do so by applying your theory + implementation in a
real-life example.
-
The easiest way to write a thesis is by attacking the problem in a Divide-and-Conquer approach.
You divide each part by asking questions. Then each question will be divided into sub-questions.
That until you reach question where the answer is simple.
Then you construct your thesis by merging all these Q&A's in an organized and logical way.
Bear in mind that the hardest part in a thesis is to find the right questions.
|
